


Avazu(艾維邑動)是一家集PC和移動互聯網廣告全球投放,全球專業移動游戲運營及發行的技術型公司。為了給客戶提供最好的廣告效果,公司自主研發的DSP平臺使用了最前沿的機器學習算法,下面就來介紹一下相關的廣告優化原理和機器學習算法。
廣告優化
眾所周知,廣告點擊率(CTR)和轉化率(CR)代表了廣告投放的效果,如何提高CTR和CR是每個廣告主都十分關心的問題。Avazu通過機器學習算法,自動地為實時流量預估CTR,廣告主只需簡單的將優化目標設置為期望CTR,DSP投放引擎即可為廣告主購買相應的優質流量,完成這一任務。如廣告主設置優化目標為CPC,則投放引擎通過將CPC轉化為期望CPM(CPM = CTR * 1000 * CPC),購買對應價格的流量。所以機器學習預測越準,廣告優化效果就越好。
機器學習
機器學習是一類從數據中自動分析獲得規律,并利用規律對未知數據進行預測的算法。由于互聯網行業的數據規模已超過人工分析能力之所及,機器學習技術幾乎成為每家互聯網公司的標配,在搜索排序,商品排序,點擊率預估,反作弊,實時競價等各種領域有著廣泛的應用。
Avazu的機器學習平臺最主要的算法包括邏輯回歸、隨機森林、深度學習,這里我們介紹邏輯回歸和深度學習。
邏輯回歸
概述
邏輯回歸(Logistic Regression)是線性模型的一種,歷史悠久,廣泛應用于各種分類任務,尤其在互聯網廣告行業中,已成為點擊率預估的基準方法。
二分類邏輯回歸的預測公式形如
p(=1|) = 1 / (1+)
p(=-1|) = / (1+)
其中,為數據特征,為模型參數,為分類目標,p(=1|)即預測為1的概率,在廣告點擊率預估中即為點擊的概率。對模型預測的y值和真實y值建立的損失函數E為LogLoss,形如
E =
最小化損失函數可使預測值與真實值差異最小。為控制模型過擬合,可以為損失函數加上正則項,常見的正則項包括w的2范數或1范數,即
E = + λ
其中為w的2范數,λ為超參數,需要通過交叉驗證(cross-validation)選取。
訓練方法
我們可以通過一些最優化(Optimization)算法來最小化損失函數,常見的最優化方法有隨機梯度下降(SGD)和L-BFGS等。
SGD是一種在線(online)算法,其特點是每次更新模型只使用少量隨機數據(通常為一個樣本),因此訓練速度很快。SGD的更新方法形如
= –
其中,為損失函數E對的梯度,為梯度下降的步長。對于步長有很多研究,一種常見的設計為
= / (1 + λt)
由于SGD的隨機性,其收斂速度和質量不是最好,可能需要迭代幾十輪(遍歷整個數據集的次數)。
L-BFGS則是一種batch算法,與online算法相反,每次更新模型都使用整個數據集,因此訓練速度較慢,但模型收斂穩定,預測質量好于SGD。
對于廣告行業來說,由于數據具有冗余性(即在整個數據集中,相同的記錄會出現多次),所以以L-BFGS為代表的batch算法在一次迭代中做了很多重復計算,因此SGD在大數據集上更受歡迎。也可以在迭代的前幾輪使用SGD,以較小的代價求得一個較好的解,再用L-BFGS繼續訓練,得到更好更穩定的解。
在大數據背景下,算法通常需要并行化。一種常見的策略是將數據隨機分成多份,每份數據各自訓練獨立的模型,最后將多個模型的參數按一定的加權辦法融合平均。其他并行/分布式訓練策略還有很多,在此不一一贅述。
稀疏數據
互聯網廣告行業的數據通產被稱為“稀疏數據”,即一行記錄只包含少量特征。舉例來說,如果我們有n個廣告商,那么整個模型關于廣告商的特征有n個,而一次曝光只含有一個廣告商,則該曝光該廣告商特征取值1,其他廣告商特征取值0。這種特征處理方式被稱為1-hot編碼。對于0值我們不做記錄也不做處理,因此稱為稀疏數據。
特征編碼與個性化
如前所述,我們對所有的特征都進行1-hot編碼,由于每個特征的編碼集大小動態變化(比如加入了新的廣告商),使得模型訓練頗為不便,所以我們使用hash方法將特征映射到固定大小的編碼集上。比如說,對設備這個特征,以二元組<“設備”,設備ID>進行hash,得到值1024,則將映射特征1024的取值為1。同時,我們還可以組成特征三元組,如<廣告商ID,“設備”,設備ID>,hash以后的特征對于每個廣告商不盡相同,則訓練出來的模型可視為廣告商個性化投放模型。
使用hash方法給特征編碼,相對于使用字典編碼,速度非常快,并且特征和模型參數也是固定的。

實驗和分析
上圖為使用一個月的Avazu日志數據訓練個性化邏輯回歸(以三元組hash編碼的形式實現,圖中x坐標軸為hash bit數)與非個性化邏輯回歸的CTR預估誤差(相對值)對比。我們可以看到,個性化模型大大提高了CTR預估的準確性。
深度學習
概述
深度學習(Deep Learning)是神經網絡的一種,即層數很多的神經網絡,其概念由Hinton于2006年提出,成為近年來神經網絡復興的標志。
深度學習的成功,最初來自于微軟研究院在語音識別上的突破,而后由Hinton帶領的小組在圖像識別任務上取得了驚人成果。
深度學習的這股熱潮,在國內機器學習業界幾乎無人不談,目前幾大互聯網公司均在嘗試,其成果以百度深度學習研究院最為突出,但應用于廣告領域,國內外尚未見大量成功案例的報道。
訓練方法
傳統的神經網絡通常只有3層(輸入層、隱層、輸出層),因多層神經網絡訓練時會遇到所謂梯度消散(vanishing gradient)的問題,故并不成功,直到2006年,Hinton提出了逐層預訓練(layer-wise pre-training)的方法才得以改善。后在2010年由James Martens提出一種Hessian-free方法使得深度學習不再需要預訓練,大為簡化。
如今的深度學習算法,回到了80年代發明的反向傳播算法,以超大的數據量,億萬級別的參數,超長的訓練時間來彌補算法的不足。下面就簡述一下反向傳播算法。
假設每一層的網絡,為如下形式
=
=
其中X為輸入層,Y為輸出層,n和n-1為層的標號,F為激勵函數,W則是模型的參數。
激勵函數的目的是使得神經網絡非線性化,否則多層的線性變換會退化為單層線性變換,也就失去意義了,常見的激勵函數包括sigmoid、tanh等。
由此,我們可以使用前向傳播算法,由下一層的輸入X求出上一層的輸出Y,而由Y的激勵函數F求
出更上一層的輸入X,直至最上層的Y。
現在定義某種形式的損失函數E,對其求偏導,根據鏈式求導法則,有

現在,我們可以使用反向傳播算法,由上一層輸入X的偏導求出該層輸出Y的偏導,而由Y的偏導求出該層W和下一層輸入X的偏導,直至最下層的W。
算出了每一層的梯度以后,就可以使用梯度下降之類的優化算法更新模型參數W。針對大數據,深度學習通常采用mini-batch的更新方法,即每次使用128或256個樣本的梯度信息更新模型。
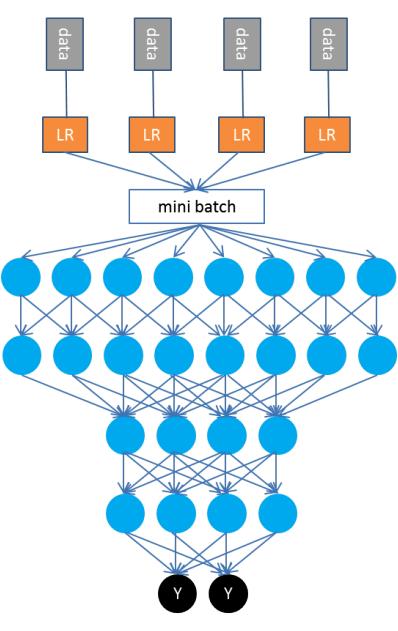
廣告數據
實際上深度學習并不能直接應用于廣告領域建模,因為如前所述,廣告數據是稀疏數據,而深度學習主要是矩陣運算,是針對稠密數據的算法。所以我們對第一層采用了預訓練的方法。具體如下:第一層依然使用邏輯回歸(LR)的并行訓練算法,每個線程使用SGD訓練自己的數據。模型接近收斂以后不做加權平均,轉而將多個模型輸出作為深度學習(DL)的輸入,訓練一個深度神經網絡。
顯然,邏輯回歸的輸出是一個稠密向量(如果有16個線程訓練,那就會輸出一個16維的向量),所有樣本的輸出則形成一個大矩陣,取其mini-batch適合于訓練深度學習模型。
實驗和分析
我們再次使用一個月的日志數據分別訓練了邏輯回歸模型和深度學習模型(都使用個性化hash),并欣喜的發現,深度學習對點擊率預估的錯誤率(以RMSE衡量)相對于邏輯回歸降低了6%之多。
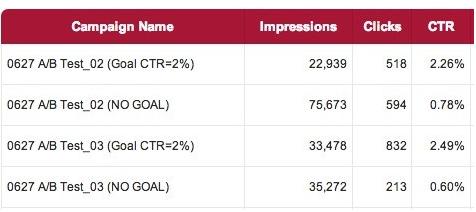
上圖為設定CTR目標前后的實際投放測試效果對比,可見使用深度學習后,DSP投放引擎將自動選擇符合目標的優質流量。
對于深度學習的提升作用,我們認為可能出于以下原因:
1. 邏輯回歸每個線程只訓練自己的數據,而深度學習則看到了所有的數據。
2. 邏輯回歸最終模型加權方式是人工指定的,而深度學習則使用了一個復雜的深度神經網絡來進行融合。
深度學習的缺點在于需要保留n份邏輯回歸模型,其預測耗時相比邏輯回歸增加了許多,所幸邏輯回歸本身計算速度非常快。
小結
Avazu DSP的機器學習技術,將廣告投放的優化工作簡化為算法自動優化。在個性化邏輯回歸的基礎上,新開發的深度學習算法又有大幅提升。那么,深度學習在廣告行業是否還有更合適的訓練方法,能否取得更好的效果?Avazu還將繼續探索。